




20 de enero de 2025 • Escrito por ILLUIN Technology y BentoML
En ILLUIN Technology, dominamos las soluciones de ingeniería y operaciones de datos y ML para la I+D y la gobernanza de nuestras soluciones de inteligencia artificial. BentoML es una piedra angular de nuestra pila MLOps para responder a problemas importantes como el empaquetado de modelos y servicios, el control de versiones, la implementación y la observabilidad.
Recientemente hemos colaborado con el equipo de BentoML para el despliegue de nuestro modelo de búsqueda visual de código abierto ColPali. Con el fin de compartir nuestros resultados, hemos redactado conjuntamente este artículo.
Introducción
Los sistemas de búsqueda documental se basan tradicionalmente en complejos procesos de ingestión de documentos, que incluyen varias etapas independientes, como el reconocimiento óptico de caracteres (OCR), el análisis del diseño o la identificación de leyendas. Integrar elementos visuales en el proceso de búsqueda es un verdadero reto e implica numerosas decisiones arbitrarias.
¿Y si pudiéramos simplificar este proceso y mejorar al mismo tiempo la precisión?
Este es el objetivo de ColPali, un modelo que combina la potencia de los modelos Vision Language Models (VLMs) y las incrustaciones multivectoriales. En este artículo, le mostramos cómo implementar una API de inferencia de ColPali funcional utilizando BentoML, lo que permite aprovechar la potencia de las incrustaciones visuales para búsquedas documentales a gran escala.
¿Qué es ColPali?
Con nuestro enfoque ColPali, utilizamos los VLM para construir embeddings multivectoriales ricos directamente a partir de imágenes de documentos («capturas de pantalla»), destinados a la búsqueda documental. Para una consulta determinada, el modelo está entrenado para maximizar la similitud entre la incrustación de esa consulta y la de la página asociada, aplicando el método de interacción tardía (o MaxSim) introducido en ColBERT (Khattab et al., 2020).
ColPali propone sustituir los complejos procesos de recuperación textual basados en OCR por un único modelo capaz de tener en cuenta tanto el contenido textual como el visual (maquetación, gráficos, etc.) de un documento. Además de su simplicidad, ColPali es más rápido y eficaz que los procesos basados en OCR, y presenta la gran ventaja de poder entrenarse de principio a fin para adaptarse a las distribuciones de datos específicas de cada sector.
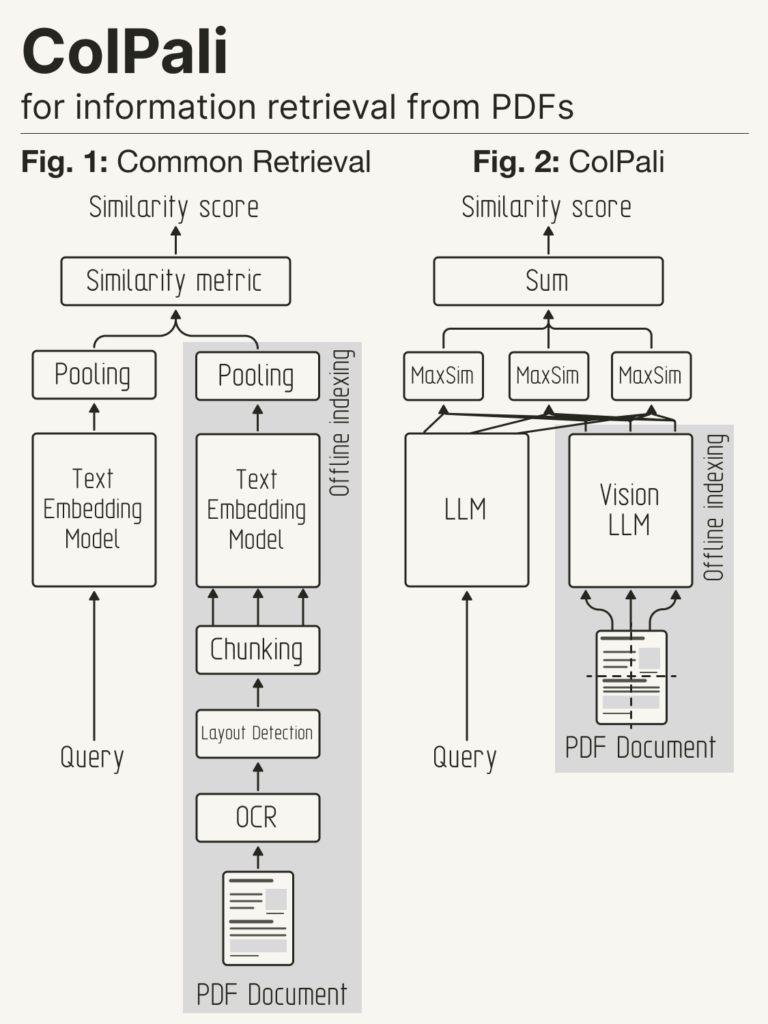
Cortesía de @helloiamleonie.
Fuente: https://x.com/helloiamleonie/status/1839321865195851859.
¿Qué es BentoML?
BentoML es una plataforma de inferencia unificada para diseñar y desarrollar sistemas de IA con cualquier modelo, en cualquier nube. Incluye:
-
-
- El marco de trabajo de código abierto para el servicio de modelos BentoML: un marco de trabajo de Python que ofrece funciones clave para la optimización de la inferencia, la puesta en cola de tareas, el procesamiento por lotes y la orquestación distribuida. Los desarrolladores pueden implementar modelos en diferentes formatos, personalizar la lógica de implementación y crear aplicaciones de IA fiables y escalables.
-
-
-
- BentoCloud: una plataforma de gestión de inferencia y un motor de orquestación de cálculos basado en el marco de código abierto BentoML. BentoCloud ofrece una pila completa para sistemas de IA rápidos y escalables, con API de Python flexibles, lanzamientos en frío ultrarrápidos y flujos de trabajo optimizados para el desarrollo, las pruebas, la implementación y la CI/CD.
-
Los retos del despliegue de ColPali
Implementar ColPali de manera eficaz plantea un desafío operativo único debido a su enfoque de incrustación multivectorial. La gran huella de memoria necesaria para almacenar y recuperar varios vectores por página/imagen de documento impone estrategias de procesamiento por lotes adaptativo para optimizar el uso de la memoria.
BentoML supera estos retos gracias a funciones como el procesamiento por lotes adaptativo y los mecanismos de E/S sin copia, lo que reduce al mínimo la sobrecarga, incluso con grandes volúmenes de datos vectoriales.
En este artículo, almacenamos los vectores en memoria para simplificar, pero para un entorno de producción escalable, se recomienda encarecidamente utilizar una base de datos vectorial. ColPali genera una representación multivectorial, un vector por sección de imagen. Sin embargo, la mayoría de las bases de datos vectoriales tradicionales almacenan un solo vector por entrada/documento.
Actualmente, solo algunas bases de datos admiten representaciones multivectoriales, como Milvus, Qdrant, Weaviate o Vespa. Otras, como Elasticsearch, están trabajando en esta funcionalidad. Para industrializar ColPali a gran escala, se recomienda elegir una base de datos vectorial adecuada para la representación multivectorial.
Configuración
Para empezar, duplique el repositorio del proyecto y colóquese en el directorio correspondiente. Contiene todo lo que necesita para la implementación.
git clone https://github.com/bentoml/BentoColPali.gitcd BentoColPali
Recomendamos crear un entorno virtual Python para aislar las dependencias:
python -m venv bento-colpali
source bento-colpali/bin/activate
Instale las dependencias necesarias:
# Recommend Python 3.11
pip install -r requirements.txt
Descargar plantilla
Antes de ejecutar el proyecto, descargue y construya el modelo ColPali. Este utiliza PaliGemma como backbone VLM.
La cuenta Hugging Face asociada al token proporcionado debe haber aceptado los términos y condiciones de google/paligemma-3b-mix-448.
python bentocolpali/models.py --model-name vidore/colpali-v1.2
--hf-token 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
Comprueba la descarga de la plantilla enumerando tus plantillas BentoML:
$ bentoml models list
Tag
Creation Time
colpali_model:mcao35vy725e6o6s
2024-12-13 03:00:15
Module Size
5.48 GiB
Implementación del modelo con BentoML
Cuando el modelo esté listo, inicie el servidor BentoML localmente:
bentoml serve .
Este comando inicia el servidor BentoLM y expone cuatro puntos finales:
http://localhost:3000:
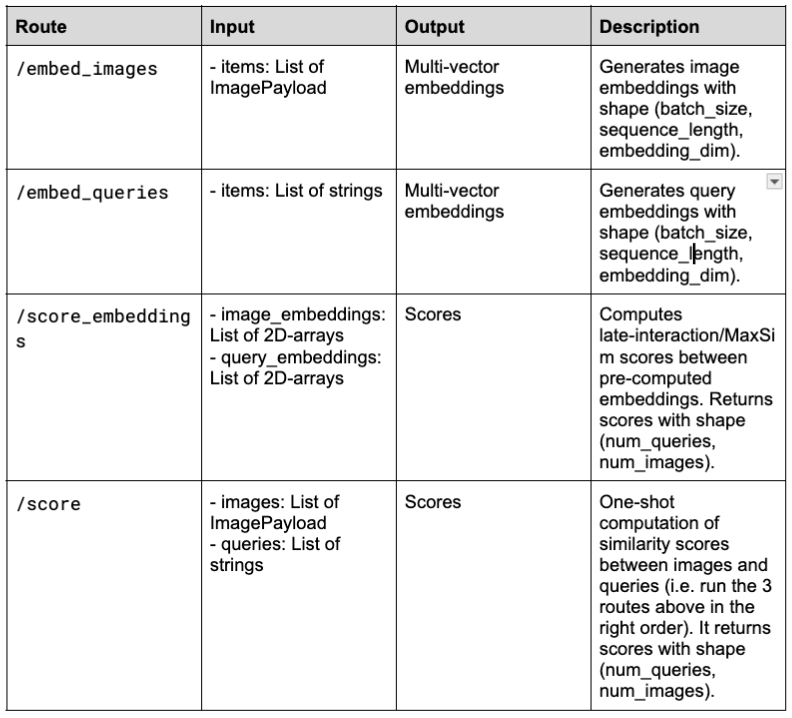
Procesamiento por lotes adaptativo
En este proyecto, el procesamiento por lotes adaptativo de BentoML está habilitado para los puntos finales /embed_images y /embed_queries. Esto ajusta dinámicamente el tamaño de los lotes y la sincronización en función del tráfico en tiempo real. Configure max_batch_size y max_latency_ms para maximizar el rendimiento y mantener una latencia aceptable.
Aquí hay un ejemplo de configuración:
# Use the @bentoml.service decorator to mark a Python class as a BentoML Service
@bentoml.service(
name="colpali",
workers=1,
traffic={"concurrency": 64}, # Set concurrency to match the batch size
)
class ColPaliService:
...
@bentoml.api(
batchable=True, # Enable adaptive batching
batch_dim=(0, 0), # The batch dimension for both input and output
max_batch_size=64, # The upper limit of the batch size
max_latency_ms=30_000, # The maximum milliseconds a batch waits to accumulate requests
)
async def embed_images(
self,
items: List[ImagePayload],
) -> np.ndarray:
...
Para obtener más información, consulte la documentación de BentoML y el código fuente completo.
Llamada a las API
Para interactuar con las API, puede crear un cliente para enviar solicitudes al servidor. A continuación se muestra un ejemplo:
import bentoml
from PIL import Image
from bentocolpali.interfaces import ImagePayload
from bentocolpali.utils import convert_pil_to_b64_image
# Prepare image payloads
image_filepaths = ["page_1.jpg", "page_2.jpg"]
image_payloads = []
for filepath in image_filepaths:
image = Image.open(filepath)
image_payloads.append(ImagePayload(url=convert_pil_to_b64_image(image)))
# Prepare queries
queries = [
"How does the positional encoding work?",
"How does the scaled dot attention product work?",
]
# Create a BentoML client and call the endpoints
with bentoml.SyncHTTPClient("http://localhost:3000") as client:
image_embeddings = client.embed_images(items=image_payloads)
query_embeddings = client.embed_queries(items=queries)
scores = client.score_embeddings(
image_embeddings=image_embeddings,
query_embeddings=query_embeddings,
)
print(scores)
Tenga en cuenta que ImagePayload requiere que las imágenes estén codificadas en base64 en el formato:
{
"url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEU..."
}
Ejemplo de resultado:
[
[16.1253643, 6.63720989],
[9.21852779, 15.88411903]
]
Implementación en BentoCloud
Una vez probada la solución localmente, implemente el servicio ColPali en BentoCloud para beneficiarse de una API de inferencia segura, escalable y fiable.
Ahora que todo funciona localmente, es el momento de implementar el servicio ColPali en BentoCloud. Esto le proporciona una API de inferencia segura, escalable y fiable.
Antes de la implementación, asegúrese de que los recursos necesarios estén especificados en el archivo bentocolpali/service.py a través del decorador @bentoml.service.
Para este ejemplo, basta con una sola GPU NVIDIA T4:
@bentoml.service(
name="colpali",
workers=1,
resources={
"gpu": 1, # The number of GPUs
"gpu_type": "nvidia-tesla-t4", # The GPU type
},
traffic={"concurrency": 64},
)
Inicie sesión en BentoCloud. Regístrese aquí de forma gratuita si aún no tiene una cuenta de BentoCloud:
bentoml cloud login
Acceda al directorio raíz de su proyecto (donde se encuentra el archivo bentofile.yaml). Ejecute el siguiente comando para implementarlo en BentoCloud y, si lo desea, defina un nombre con la opción -n:
bentoml deploy . -n colpali-bento
Una vez finalizada la implementación, podrá encontrarla en la sección Implementaciones.
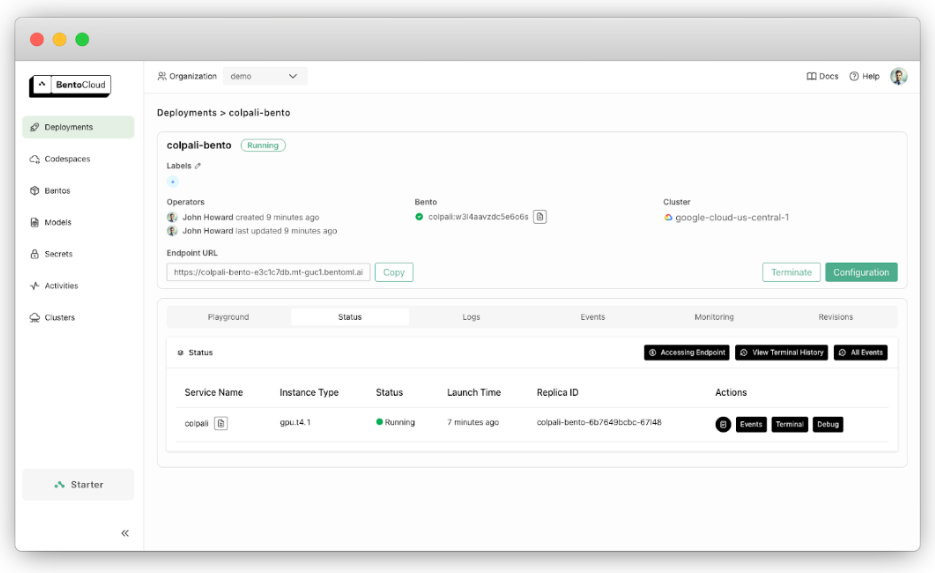
Para consultar la URL expuesta, utilice:
bentoml deployment get colpali-bento -o json | jq ."endpoint_urls"
Reemplace http://localhost:3000 en el código anterior del cliente por la URL recuperada y podrá realizar las mismas llamadas a la API.
De forma predeterminada, la implementación tiene una sola réplica, pero puede adaptarla a sus necesidades. Por ejemplo, para pasar de 0 a 5 réplicas, utilice:
bentoml deployment update colpali-bento --scaling-min 0 --scaling-max 5
Esto minimiza el uso de recursos durante los periodos de inactividad, al tiempo que gestiona eficazmente el tráfico elevado gracias a un tiempo de arranque en frío rápido.
Conclusión
En este tutorial, hemos mostrado cómo implementar ColPali con BentoML para crear una API de inferencia que comprenda tanto el contenido textual como el visual sin necesidad de complejos procesos de OCR. La solución se puede implementar fácilmente de forma local o escalable en producción con BentoCloud. ¡Pruébela para simplificar sus flujos de trabajo de procesamiento de documentos!
Más recursos:





