




20. Januar 2025 • Verfasst von ILLUIN Technology und BentoML
Bei ILLUIN Technology beherrschen wir Daten- und ML-Engineering-/Ops-Lösungen für die Forschung und Entwicklung sowie die Governance unserer Lösungen im Bereich der künstlichen Intelligenz. BentoML ist ein Eckpfeiler unseres MLOps-Stacks, um wichtige Probleme wie die Verpackung von Modellen und Diensten, Versionierung, Bereitstellung und Beobachtbarkeit zu lösen.
Wir haben kürzlich mit dem BentoML-Team bei der Bereitstellung unseres Open-Source-Modells für die visuelle Suche ColPali zusammengearbeitet. Um unsere Ergebnisse zu teilen, haben wir gemeinsam diesen Artikel verfasst.
Einführung
Dokumentensuchsysteme basieren traditionell auf komplexen Pipelines zur Dokumentenerfassung, die mehrere unabhängige Schritte wie OCR, Layoutanalyse oder Bildunterschriftenerkennung umfassen. Die Integration visueller Elemente in den Suchprozess ist eine echte Herausforderung und erfordert zahlreiche willkürliche Entscheidungen.
Was wäre, wenn wir diesen Prozess vereinfachen und gleichzeitig die Genauigkeit verbessern könnten?
Das ist das Ziel von ColPali, einem Modell, das die Leistungsfähigkeit von Vision Language Models (VLMs) und Multi-Vektor-Embeddings kombiniert. In diesem Artikel zeigen wir Ihnen, wie Sie mit BentoML eine funktionsfähige ColPali-Inferenz-API bereitstellen können, mit der Sie die Leistungsfähigkeit visueller Embeddings für groß angelegte Dokumentensuchen nutzen können.
Was ist ColPali?
Mit unserem ColPali-Ansatz verwenden wir VLMs, um direkt aus Dokumentbildern („Screenshots“) reichhaltige Multi-Vektor-Einbettungen für die Dokumentensuche zu erstellen. Für eine bestimmte Abfrage wird das Modell darauf trainiert, die Ähnlichkeit zwischen der Einbettung dieser Abfrage und der der zugehörigen Seite zu maximieren, indem die in ColBERT (Khattab et al., 2020) eingeführte Methode der späten Interaktion (oder MaxSim) angewendet wird.
ColPali ersetzt komplexe OCR-basierte Textabruf-Pipelines durch ein einziges Modell, das sowohl den Text- als auch den Bildinhalt (Layout, Grafiken usw.) eines Dokuments berücksichtigen kann. ColPali ist nicht nur einfach zu bedienen, sondern auch schneller und leistungsfähiger als OCR-basierte Pipelines und bietet den großen Vorteil, dass es von Anfang bis Ende trainiert werden kann, um an die spezifischen Datenverteilungen jeder Branche angepasst zu werden.
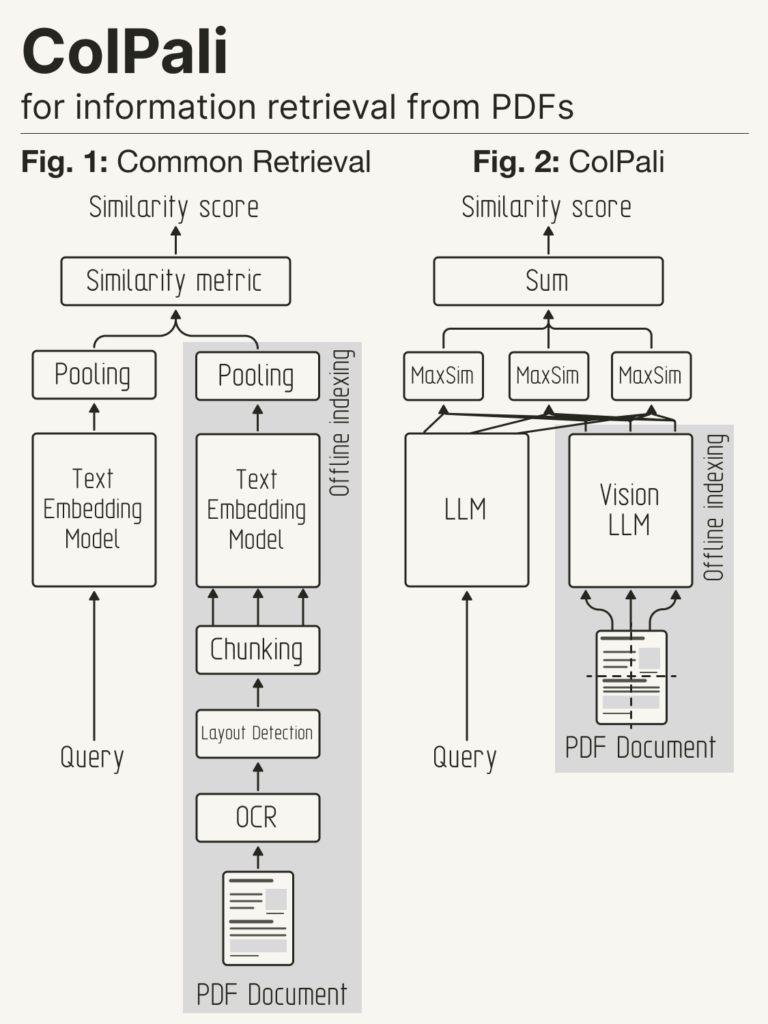
Mit freundlicher Genehmigung von @helloiamleonie.
Quelle: https://x.com/helloiamleonie/status/1839321865195851859.
Was ist BentoML?
BentoML ist eine einheitliche Inferenzplattform zum Entwerfen und Weiterentwickeln von KI-Systemen mit beliebigen Modellen in beliebigen Clouds. Sie umfasst:
-
-
- Das Open-Source-Framework BentoML für Model Serving: Ein Python-Framework mit wichtigen Funktionen für die Optimierung der Inferenz, die Aufgabenwarteschlange, das Batching und die verteilte Orchestrierung. Entwickler können Modelle in verschiedenen Formaten bereitstellen, die Bereitstellungslogik anpassen und zuverlässige, skalierbare KI-Anwendungen erstellen.
-
-
-
- BentoCloud: Eine Plattform für das Inferenzmanagement und eine Berechnungsorchestrierungs-Engine, die auf dem Open-Source-Framework BentoML basiert. BentoCloud bietet einen kompletten Stack für schnelle und skalierbare KI-Systeme mit flexiblen Python-APIs, ultraschnellen Kaltstarts und optimierten Workflows für Entwicklung, Tests, Bereitstellung und CI/CD.
-
Die Herausforderungen bei der Einführung von ColPali
Die effektive Bereitstellung von ColPali stellt aufgrund seines Multi-Vektor-Einbettungsansatzes eine einzigartige operative Herausforderung dar. Der große Speicherbedarf für die Speicherung und den Abruf mehrerer Vektoren pro Seite/Dokumentbild erfordert adaptive Batching-Strategien, um die Speichernutzung zu optimieren.
BentoML bewältigt diese Herausforderungen mit Funktionen wie adaptivem Batching und Zero-Copy-I/O-Mechanismen, wodurch der Overhead selbst bei großen Mengen an Vektordaten auf ein Minimum reduziert wird.
In diesem Artikel speichern wir die Vektoren der Einfachheit halber im Speicher, aber für eine skalierbare Produktionsumgebung wird eine Vektordatenbank dringend empfohlen. ColPali generiert eine Multi-Vektor-Darstellung, einen Vektor pro Bildausschnitt. Die meisten herkömmlichen Vektordatenbanken speichern jedoch nur einen Vektor pro Eintrag/Dokument.
Derzeit unterstützen nur wenige Datenbanken Multivektor-Darstellungen, darunter Milvus, Qdrant, Weaviate oder Vespa. Andere, wie Elasticsearch, arbeiten an dieser Funktion. Um ColPali in großem Maßstab zu industrialisieren, wird empfohlen, eine Vektordatenbank zu wählen, die für die Multivektor-Darstellung geeignet ist.
Einrichtung
Duplizieren Sie zunächst das Projekt-Repository und wechseln Sie in das entsprechende Verzeichnis. Es enthält alles, was Sie für die Bereitstellung benötigen.
git clone https://github.com/bentoml/BentoColPali.gitcd BentoColPali
Wir empfehlen Ihnen, eine virtuelle Python-Umgebung zu erstellen, um Abhängigkeiten zu isolieren:
python -m venv bento-colpali
source bento-colpali/bin/activate
Installieren Sie die erforderlichen Abhängigkeiten:
# Recommend Python 3.11
pip install -r requirements.txt
Vorlage herunterladen
Bevor Sie das Projekt ausführen, laden Sie die ColPali-Vorlage herunter und erstellen Sie sie. Diese verwendet PaliGemma als VLM-Backbone.
Das mit dem bereitgestellten Token verknüpfte Hugging Face-Konto muss die Allgemeinen Geschäftsbedingungen von google/paligemma-3b-mix-448 akzeptiert haben.
python bentocolpali/models.py --model-name vidore/colpali-v1.2
--hf-token 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
Überprüfen Sie den Download der Vorlage, indem Sie Ihre BentoML-Vorlagen auflisten:
$ bentoml models list
Tag
Creation Time
colpali_model:mcao35vy725e6o6s
2024-12-13 03:00:15
Module Size
5.48 GiB
Bereitstellung des Modells mit BentoML
Wenn das Modell fertig ist, starten Sie den BentoML-Server lokal:
bentoml serve .
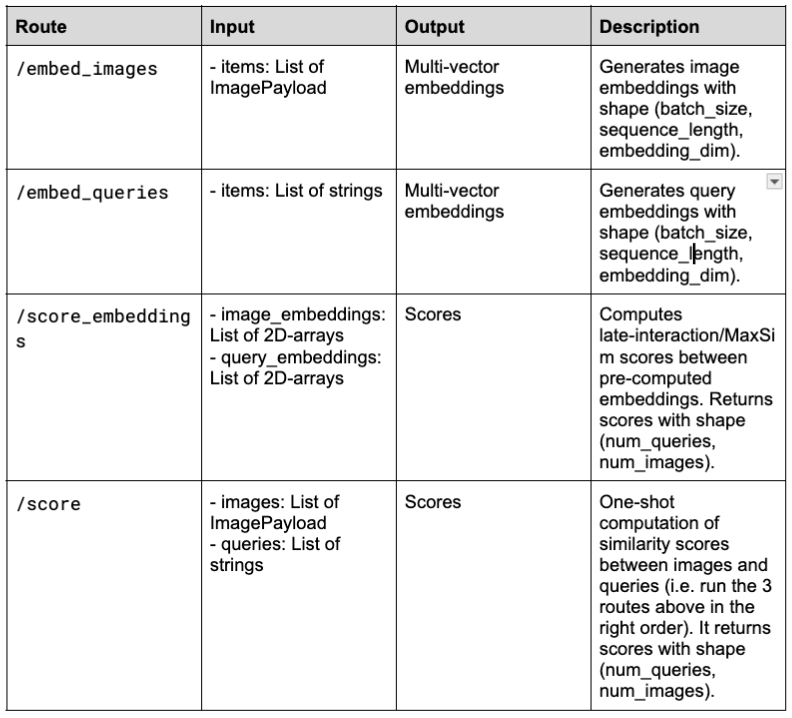
Dieser Befehl startet den BentoLM-Server und stellt vier Endpunkte bereit:
http://localhost:3000:
Adaptives Batching
In diesem Projekt ist das adaptive Batching von BentoML für die Endpunkte /embed_images und /embed_queries aktiviert. Dadurch werden die Stapelgröße und das Timing dynamisch an den Echtzeit-Datenverkehr angepasst. Konfigurieren Sie max_batch_size und max_latency_ms, um den Durchsatz zu maximieren und gleichzeitig eine akzeptable Latenz aufrechtzuerhalten.
Hier ein Beispiel für eine Konfiguration:
# Use the @bentoml.service decorator to mark a Python class as a BentoML Service
@bentoml.service(
name="colpali",
workers=1,
traffic={"concurrency": 64}, # Set concurrency to match the batch size
)
class ColPaliService:
...
@bentoml.api(
batchable=True, # Enable adaptive batching
batch_dim=(0, 0), # The batch dimension for both input and output
max_batch_size=64, # The upper limit of the batch size
max_latency_ms=30_000, # The maximum milliseconds a batch waits to accumulate requests
)
async def embed_images(
self,
items: List[ImagePayload],
) -> np.ndarray:
...
Mehr erfahren finden Sie in der BentoML-Dokumentation und im vollständigen Quellcode.
Aufruf an APIs
Um mit den APIs zu interagieren, können Sie einen Client erstellen, um Anfragen an den Server zu senden. Hier ein Beispiel:
import bentoml
from PIL import Image
from bentocolpali.interfaces import ImagePayload
from bentocolpali.utils import convert_pil_to_b64_image
# Prepare image payloads
image_filepaths = ["page_1.jpg", "page_2.jpg"]
image_payloads = []
for filepath in image_filepaths:
image = Image.open(filepath)
image_payloads.append(ImagePayload(url=convert_pil_to_b64_image(image)))
# Prepare queries
queries = [
"How does the positional encoding work?",
"How does the scaled dot attention product work?",
]
# Create a BentoML client and call the endpoints
with bentoml.SyncHTTPClient("http://localhost:3000") as client:
image_embeddings = client.embed_images(items=image_payloads)
query_embeddings = client.embed_queries(items=queries)
scores = client.score_embeddings(
image_embeddings=image_embeddings,
query_embeddings=query_embeddings,
)
print(scores)
Beachten Sie, dass ImagePayload eine Base64-Kodierung der Bilder im folgenden Format erfordert:
{
"url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEU..."
}
Beispiel für ein Ergebnis:
[
[16.1253643, 6.63720989],
[9.21852779, 15.88411903]
]
Bereitstellung auf BentoCloud
Sobald Sie die Lösung lokal getestet haben, stellen Sie den ColPali-Dienst auf BentoCloud bereit, um von einer sicheren, skalierbaren und zuverlässigen Inferenz-API zu profitieren.
Nachdem nun alles lokal funktioniert, ist es an der Zeit, den ColPali-Dienst auf BentoCloud bereitzustellen. Damit erhalten Sie eine sichere, skalierbare und zuverlässige Inferenz-API.
Stellen Sie vor der Bereitstellung sicher, dass die erforderlichen Ressourcen in der Datei bentocolpali/service.py über den Dekorator @bentoml.service angegeben sind.
Für dieses Beispiel ist eine einzige NVIDIA T4-GPU ausreichend:
@bentoml.service(
name="colpali",
workers=1,
resources={
"gpu": 1, # The number of GPUs
"gpu_type": "nvidia-tesla-t4", # The GPU type
},
traffic={"concurrency": 64},
)
Melden Sie sich bei BentoCloud an. Registrieren Sie sich hier kostenlos, wenn Sie noch kein BentoCloud-Konto haben:
bentoml cloud login
Wechseln Sie in das Stammverzeichnis Ihres Projekts (wo sich die Datei bentofile.yaml befindet). Führen Sie den folgenden Befehl aus, um es auf BentoCloud bereitzustellen und gegebenenfalls einen Namen mit der Option -n festzulegen:
bentoml deploy . -n colpali-bento
Sobald die Bereitstellung abgeschlossen ist, finden Sie sie im Abschnitt „Bereitstellungen”.
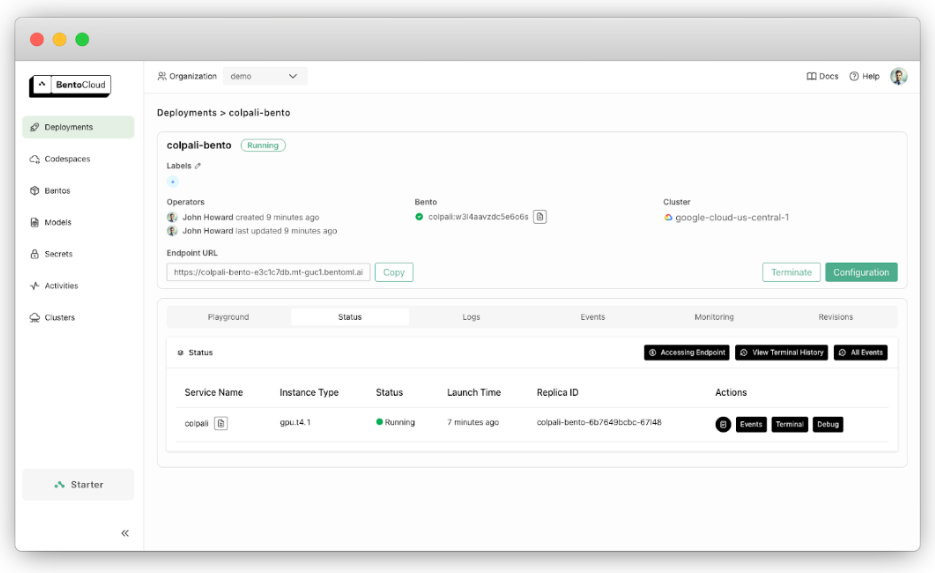
Um die angegebene URL aufzurufen, verwenden Sie:
bentoml deployment get colpali-bento -o json | jq ."endpoint_urls"
Ersetzen Sie http://localhost:3000 im obigen Kundencode durch die abgerufene URL, und Sie können dieselben API-Aufrufe ausführen.
Standardmäßig verfügt die Bereitstellung über ein einziges Replikat, aber Sie können dies an Ihre Anforderungen anpassen. Um beispielsweise von 0 auf 5 Replikate zu wechseln, verwenden Sie:
bentoml deployment update colpali-bento --scaling-min 0 --scaling-max 5
Dadurch wird der Ressourcenverbrauch in Zeiten geringer Auslastung minimiert und gleichzeitig ein hoher Datenverkehr dank einer schnellen Kaltstartzeit effizient bewältigt.
Fazit
In diesem Tutorial haben wir gezeigt, wie ColPali mit BentoML eingesetzt werden kann, um eine Inferenz-API zu erstellen, die sowohl Text- als auch Bildinhalte versteht, ohne dass komplexe OCR-Pipelines erforderlich sind. Die Lösung lässt sich lokal oder skalierbar in der Produktion mit BentoCloud einfach einsetzen. Probieren Sie sie aus, um Ihre Dokumentenverarbeitungs-Workflows zu vereinfachen!
Weitere Ressourcen:





