



")
ILLUIN Technology et CentraleSupélec sont fiers de présenter une nouvelle approche innovante dans le domaine du Retrieval-Augmented Generation (RAG) appliqué à des corpus documentaires complexes avec ColPali : Efficient Document Retrieval with Vision Language Models.
Rechercher l’information dans des documents complexes
Face à la difficulté de rechercher efficacement des informations dans des documents complexes – intégrant souvent des images, tableaux, et diagrammes – nous avons travaillé à développer une solution innovante. Cette nouvelle approche s’intègre à nos produits (ILLUIN Search et ILLUIN Dialogue), ainsi qu’aux projets de GenAI sur mesure que nous réalisons.
Les pipelines traditionnelles d’indexation documentaire se déroulent en deux étapes principales :
- 🔄 Utilisation de nombreux modèles de computer vision pour comprendre la structure du document et en extraire le texte.
- 🗂️ Indexation du texte en utilisant des représentations textuelles pour une étape ultérieure de retrieving (récupération).
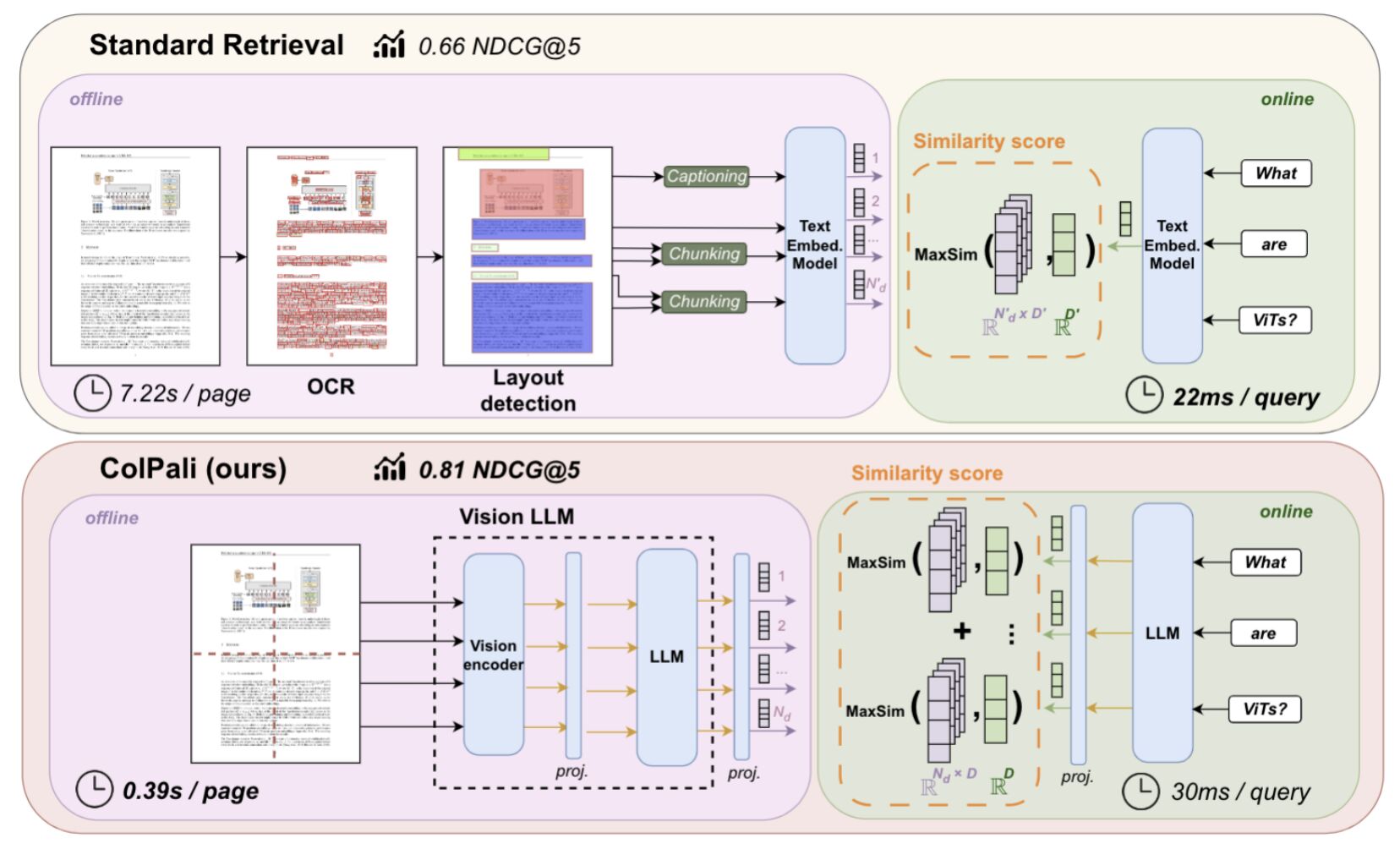
Cependant, cette méthode présente des limites : lenteur, propagation d’erreurs, et une compréhension limitée des éléments visuels d’un document. Pour remédier à ces inconvénients, nous avons développé une représentation du document plus adaptée.
Les contributions principales de cette avancée
Deux contributions principales sont ainsi présentées dans cette publication :
- 📚 Le benchmark ViDoRe (Visual Document Retrieval) : le premier benchmark open-source qui évalue la qualité des retrievers dans la recherche d’informations visuellement riches au sein de documents complexes.
- 🤖 Le modèle ColPali : une approche novatrice basée sur le modèle VLM PaliGemma de Google, créant une représentation multi-vectorielle du document. Ce modèle utilise le mécanisme de “late interaction” de Colbert pour un matching précis et efficace des tokens de la requête avec les patches du document lors de l’inférence.
Des résultats prometteurs
ColPali se distingue par des performances et une rapidité supérieures à d’autres méthodes, y compris celles basées sur le captioning d’images avec le modèle Claude Sonnet d’Anthropic. Cette avancée démontre le potentiel des Vision Language Models (VLM) pour le retrieving documentaire. 📈
Pour en savoir plus, consultez la publication complète sur arxiv.org et découvrez davantage sur :
- L’organisation HuggingFace
- Le blogpost de Manuel Faysse
Remerciements
Un très grand bravo à tous les contributeurs : Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Celine Hudelot, Pierre Colombo ainsi qu’à l’équipe du CINES pour les ressources de calculs sur ADASTRA. 👏
CC : Robert VESOUL, Wacim Belblidia, Paul-Henry Cournède, Renaud Monnet





