




20 janvier 2025 • Ecrit par ILLUIN Technology et BentoML
Chez ILLUIN Technology, nous maîtrisons les solutions de data et ML engineering / Ops pour la R&D et la gouvernance de nos solutions en intelligence artificielle. BentoML est une pierre angulaire de notre stack MLOps pour répondre à des problématiques majeures telles que le packaging des modèles et des services, le versionning , le déploiement et l’observabilité.
Nous avons récemment collaboré avec l’équipe de BentoML pour le déploiement de notre modèle open-source de recherche visuelleColPali. Afin de partager nos résultats, nous avons rédigé ensemble cet article.
Introduction
Les systèmes de recherche documentaire reposent traditionnellement sur des pipelines complexes d’ingestion de documents, comprenant plusieurs étapes indépendantes telles que l’OCR, l’analyse de mise en page ou encore l’identification des légendes. Intégrer des éléments visuels dans le processus de recherche est un réel défi et implique de nombreux choix arbitraires.
Et si nous pouvions simplifier ce processus tout en améliorant la précision ?
C’est l’objectif de ColPali, un modèle combinant la puissance des modèles Vision Language Models (VLMs) et des embeddings multi-vecteurs. Dans cet article, nous vous montrons comment déployer une API d’inférence de ColPali fonctionnelle à l’aide de BentoML, permettant d’exploiter la puissance des embeddings visuels pour des recherches documentaires à grande échelle.
Qu’est-ce que ColPali ?
Avec notre approche ColPali, nous utilisons les VLMs pour construire des embeddings multi-vecteurs riches directement à partir d’images de documents (« captures d’écran »), destinés à la recherche documentaire. Pour une query donnée, le modèle est entraîné à maximiser la similarité entre l’embedding de cette query et celle de la page associée, en appliquant la méthode de late interaction (ou MaxSim) introduite dans ColBERT (Khattab et al., 2020).
ColPali se propose de remplacer les pipelines de retrieval textuel complexes à base d’OCR avec un unique modèle capable de prendre en compte à la fois le contenu textuel et visuel (mise en page, graphiques, etc…) d’un document. En plus de sa simplicité, ColPali est plus rapide et plus performante que les pipelines à base d’OCR, et présente l’atout majeur de pouvoir être entraîné de bout en bout pour être adapté aux distributions de données spécifiques à chaque industrie.
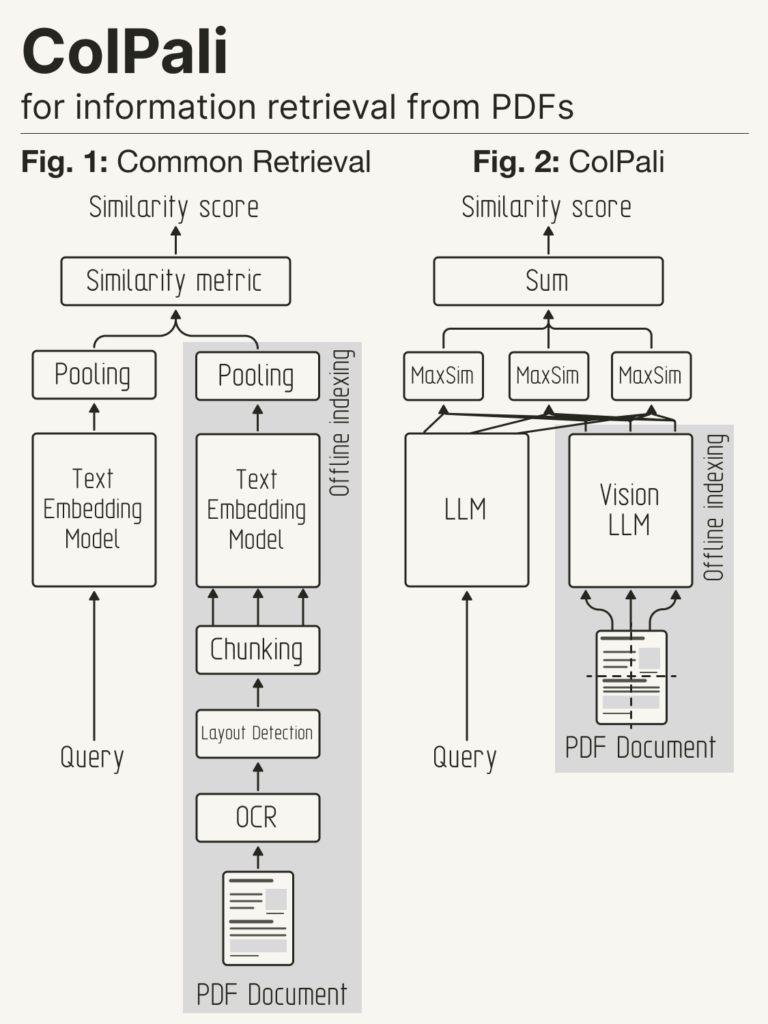
Courtesy of @helloiamleonie.
Source : https://x.com/helloiamleonie/status/1839321865195851859.
Qu’est-ce que BentoML ?
BentoML est une plateforme unifiée d’inférence pour concevoir et faire évoluer des systèmes d’IA avec n’importe quel modèle, sur n’importe quel cloud. Elle comprend :
-
-
- le Framework de model serving open-source BentoML : un framework Python offrant des fonctionnalités clés pour l’optimisation d’inférence, le queuing de tâches, le batching et l’orchestration distribuée. Les développeurs peuvent déployer des modèles dans différents formats, personnaliser la logique de déploiement et construire des applications d’IA fiables et scalables.
-
-
-
- BentoCloud : une plateforme de gestion de l’inférence et un moteur d’orchestration de calcul basé sur le framework open-source BentoML. BentoCloud propose une pile complète pour des systèmes IA rapides et scalables, avec des API Python flexibles, des lancements à froid ultra-rapides et des workflows optimisés pour le développement, les tests, le déploiement et la CI/CD.
-
Les Défis du déploiement de ColPali
Déployer ColPali efficacement pose un défi opérationnel unique en raison de son approche d’embedding multi-vecteurs. La grande empreinte mémoire nécessaire pour stocker et récupérer plusieurs vecteurs par page/image de document impose des stratégies d’adaptive batching pour optimiser l’utilisation de la mémoire.
BentoML relève ces défis grâce à des fonctionnalités telles que l’adaptive batching et les mécanismes d’I/O zero copy, réduisant au minimum la surcharge, même avec de gros volumes de données vectorielles.
Dans cet article, nous stockons les vecteurs en mémoire pour simplifier, mais pour un environnement de production scalable, une base de données vectorielle est fortement recommandée. ColPali génère une représentation multi-vecteurs, un vecteur par section d’image. Toutefois, la plupart des bases de données vectorielles traditionnelles stockent un seul vecteur par entrée/document.
Actuellement, seules quelques bases supportent les représentations multi-vecteurs, telles que Milvus, Qdrant, Weaviate, or Vespa. D’autres, comme Elasticsearch, travaillent sur cette fonctionnalité. Pour industrialiser ColPali à grande échelle, il est recommandé de choisir une base de données vectorielle adaptée à la représentation multi-vecteurs.
Setup
Pour commencer, dupliquez le repository du projet et placez-vous dans le répertoire concerné. Il contient tout ce dont vous avez besoin pour le déploiement.
git clone https://github.com/bentoml/BentoColPali.gitcd BentoColPali
Nous vous recommandons de créer un environnement virtuel Python pour isoler les dépendances :
python -m venv bento-colpali
source bento-colpali/bin/activate
Installez les dépendances requises :
# Recommend Python 3.11
pip install -r requirements.txt
Téléchargement du modèle
Avant d’exécuter le projet, téléchargez et construisez le modèle ColPali. Celui-ci utilise PaliGemma comme backbone VLM.
Le compte Hugging Face associé au token fourni doit avoir accepté les conditions générales de google/paligemma-3b-mix-448.
python bentocolpali/models.py --model-name vidore/colpali-v1.2
--hf-token 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
Vérifiez le téléchargement du modèle en listant vos modèles BentoML:
$ bentoml models list
Tag
Creation Time
colpali_model:mcao35vy725e6o6s
2024-12-13 03:00:15
Module Size
5.48 GiB
Déploiement du modèle avec BentoML
Quand le modèle est prêt, lancez le serveur BentoML localement:
bentoml serve .
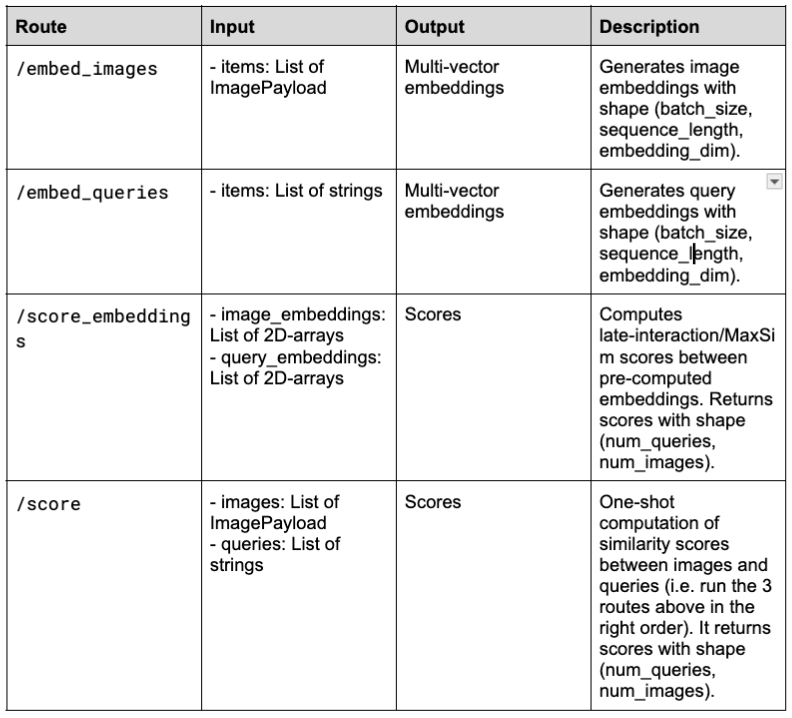
Cette commande déclenche le serveur BentoLM et expose quatre endpoints :
http://localhost:3000:
Adaptative Batching
Dans ce projet, l’adaptive batching de BentoML est activé pour les endpoints /embed_images et /embed_queries. Cela ajuste dynamiquement la taille des lots et le timing en fonction du trafic en temps réel. Configurez max_batch_size et max_latency_ms pour maximiser le débit tout en maintenant une latence acceptable.
Voici un exemple de configuration :
# Use the @bentoml.service decorator to mark a Python class as a BentoML Service
@bentoml.service(
name="colpali",
workers=1,
traffic={"concurrency": 64}, # Set concurrency to match the batch size
)
class ColPaliService:
...
@bentoml.api(
batchable=True, # Enable adaptive batching
batch_dim=(0, 0), # The batch dimension for both input and output
max_batch_size=64, # The upper limit of the batch size
max_latency_ms=30_000, # The maximum milliseconds a batch waits to accumulate requests
)
async def embed_images(
self,
items: List[ImagePayload],
) -> np.ndarray:
...
Pour plus d’informations, consultez la documentation BentoML et le code source complet.
Appel à APIs
Pour interagir avec les APIs, vous pouvez créer un client pour envoyer des requêtes au serveur. Voici un exemple :
import bentoml
from PIL import Image
from bentocolpali.interfaces import ImagePayload
from bentocolpali.utils import convert_pil_to_b64_image
# Prepare image payloads
image_filepaths = ["page_1.jpg", "page_2.jpg"]
image_payloads = []
for filepath in image_filepaths:
image = Image.open(filepath)
image_payloads.append(ImagePayload(url=convert_pil_to_b64_image(image)))
# Prepare queries
queries = [
"How does the positional encoding work?",
"How does the scaled dot attention product work?",
]
# Create a BentoML client and call the endpoints
with bentoml.SyncHTTPClient("http://localhost:3000") as client:
image_embeddings = client.embed_images(items=image_payloads)
query_embeddings = client.embed_queries(items=queries)
scores = client.score_embeddings(
image_embeddings=image_embeddings,
query_embeddings=query_embeddings,
)
print(scores)
Notez que ImagePayload nécessite que les images un encodage base64 dans le format:
{
"url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEU..."
}
Exemple de résultat :
[
[16.1253643, 6.63720989],
[9.21852779, 15.88411903]
]
Déploiement sur BentoCloud
Une fois la solution testée en local, déployez le service ColPali sur BentoCloud pour bénéficier d’une API d’inférence sécurisée, scalable et fiable.
Maintenant que tout fonctionne localement, il est temps de déployer le service ColPali vers BentoCloud. Cela vous donne une API d’inférence sécurisée, scalable et fiable.
Avant le déploiement, assurez-vous que les ressources nécessaires sont spécifiées dans le fichier bentocolpali/service.py via le décorateur @bentoml.service.
Pour cet exemple, un seul GPU NVIDIA T4 est suffisant :
@bentoml.service(
name="colpali",
workers=1,
resources={
"gpu": 1, # The number of GPUs
"gpu_type": "nvidia-tesla-t4", # The GPU type
},
traffic={"concurrency": 64},
)
Connectez-vous à BentoCloud. Sign-up ici gratuitement si vous n’avez pas de compte BentoCloud:
bentoml cloud login
Accédez au répertoire racine de votre projet (là où se trouve le fichier bentofile.yaml). Exécutez la commande suivante pour le déployer sur BentoCloud et, éventuellement, définir un nom avec l’option -n:
bentoml deploy . -n colpali-bento
Une fois le déploiement finalisé, vous pouvez le retrouver dans la section des Déploiements.
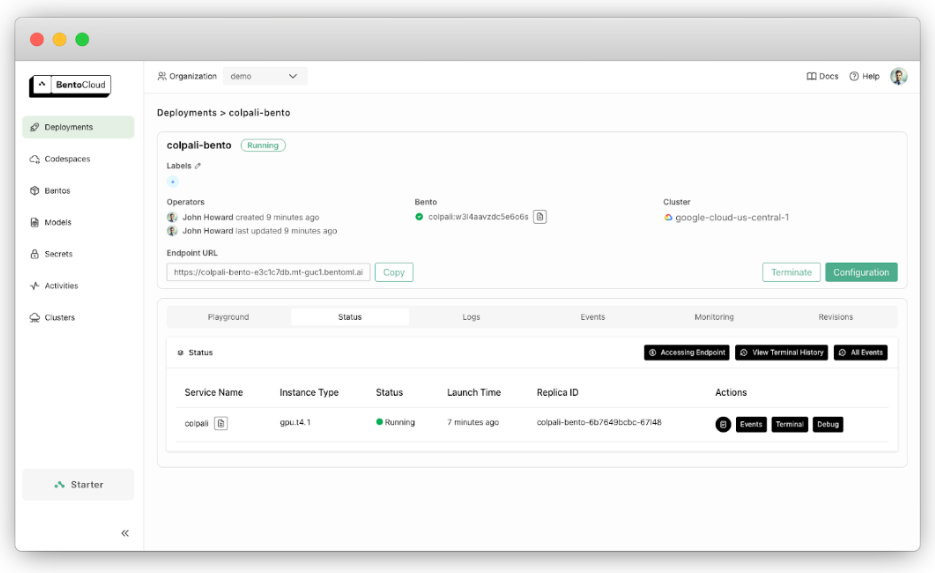
Pour consulter l’URL exposée, utilisez :
bentoml deployment get colpali-bento -o json | jq ."endpoint_urls"
Remplacez http://localhost:3000 dans le code client précédent par l’URL récupérée, et vous pourrez effectuer les mêmes appels API.
Par défaut, le déploiement dispose d’une seule réplique, mais vous pouvez l’adapter à vos besoins. Par exemple, pour passer de 0 à 5 répliques, utilisez :
bentoml deployment update colpali-bento --scaling-min 0 --scaling-max 5
Cela minimise l’utilisation des ressources pendant les périodes d’inactivité tout en gérant efficacement un trafic élevé grâce à un temps de lancement à froid rapide.
Conclusion
Dans ce tutoriel, nous avons montré comment déployer ColPali avec BentoML pour créer une API d’inférence qui comprend à la fois le contenu textuel et visuel sans nécessiter de pipelines OCR complexes. La solution est facilement déployable localement ou de manière scalable en production avec BentoCloud. Essayez-la pour simplifier vos workflows de traitement documentaire !
Plus de ressources :





